Even the best-trained robots struggle when they leave the lab. They face “distribution shifts”—situations they didn’t see in training, like a brand of cereal with a new box design or a human suddenly walking into their personal space. Static datasets (fixed instructions) simply can’t prepare a robot for every “what if” scenario.
To make sense of all this messy real-world data, the researchers introduced two key technical innovations to the robot’s “Vision-Language-Action” (VLA) brain.
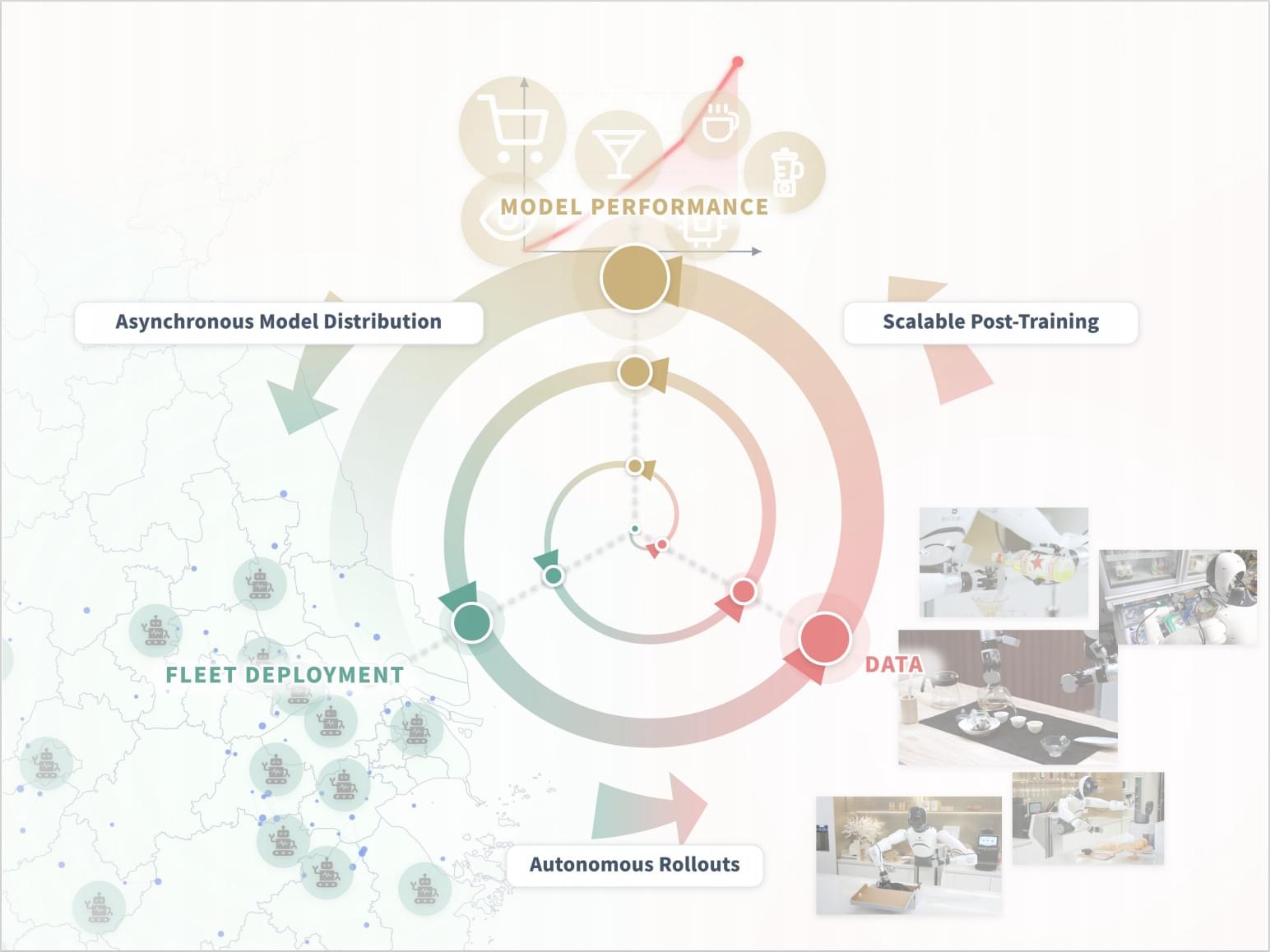
Imagine bringing home a single robot to be your all-in-one kitchen assistant—you want it to brew your morning Gongfu tea, make fresh juice in the afternoon, and mix the perfect cocktail at night. While it might have been trained extensively in a lab, in your house, the counter is slightly higher, the fruit is shaped differently, and your cocktail shaker is transparent. Pre-trained Vision-Language-Action (VLA) models provide an incredible starting point, yet real-world deployment is never a fixed test distribution. This leaves a critical, unsolved challenge: how do we take the heterogeneous experience generated across a fleet of robots and use it to post-train a single, generalist model across a wide range of tasks simultaneously?
We present Learning While Deploying (LWD), a fleet-scale offline-to-online RL framework for continual post-training of generalist VLA policies. Instead of treating deployment as the finish line where a policy is merely evaluated, LWD turns it into a training loop through which the policy improves. A pre-trained policy is deployed across a robot fleet, and both autonomous rollouts and human interventions are aggregated into a shared replay buffer for offline and online updates. The updated policy is then redeployed, enabling continuous improvement by leveraging interaction data from the entire fleet.
A Generalist Learns Beyond Demonstrations
Some robot learning systems have explored data flywheels: deploying a policy, collecting new robot data, extracting high-quality behaviors, and training the next policy to imitate them. While this supports scalable improvement, it still treats deployment mainly as a source of expert demonstrations. Prior post-training systems mainly focus on specialist policies, leaving fleet-scale post-training of a single generalist policy across diverse tasks unresolved.