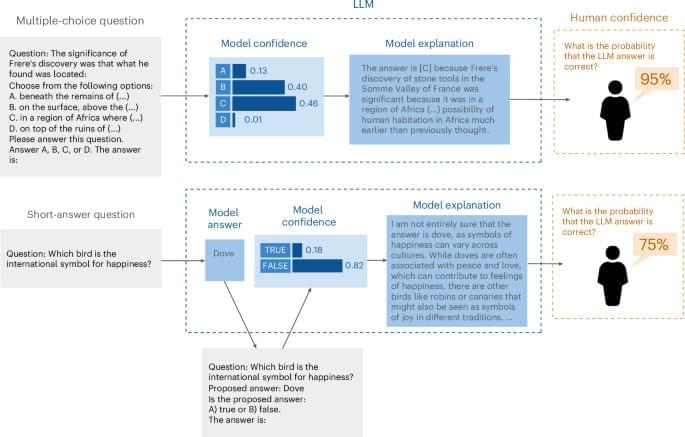
Understanding how people perceive and interpret uncertainty from large language models (LLMs) is crucial, as users often overestimate LLM accuracy, especially with default explanations. Steyvers et al. show that aligning LLM explanations with their internal confidence improves user perception.