Cerebras has set a new record for AI inference speed, serving Llama 3.1 8B at 1,850 output tokens/s and 70B at 446 output tokens/s.
@CerebrasSystems has just launched their API inference offering, powered by their custom wafer-scale AI accelerator chips.
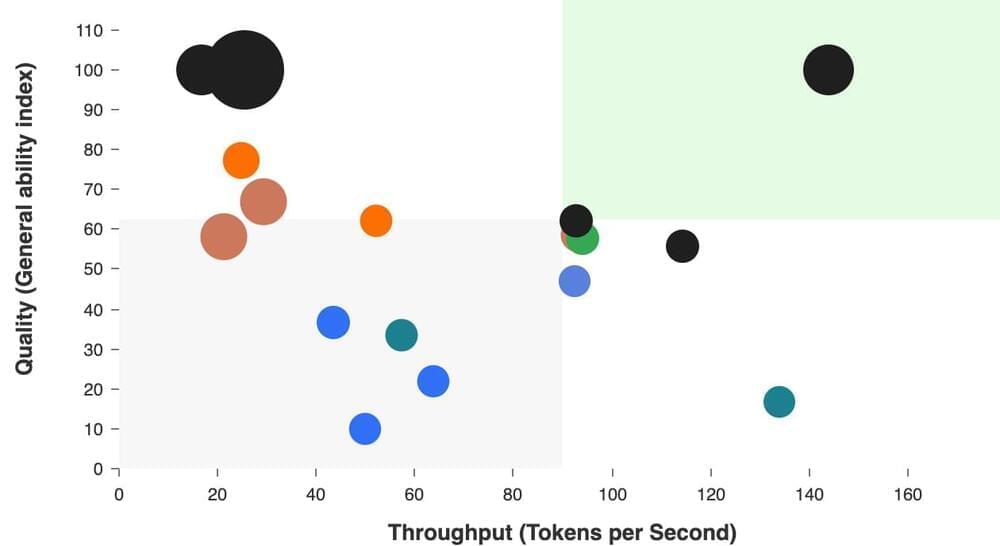
Llama 3.1 8B provider analysis:
Analysis of API for Llama 3.1 Instruct 8B across performance metrics including latency (time to first token), output speed (output tokens per second), price and others. API benchmarked include Microsoft Azure, Amazon Bedrock, Groq, Together.ai, Perplexity, Fireworks, Cerebras, Lepton AI, Deepinfra, and OctoAI.