It’s no secret that OpenAI’s ChatGPT has some incredible capabilities—for instance, the chatbot can write poetry that resembles Shakespearean sonnets or debug code for a computer program. These abilities are made possible by the massive machine-learning model that ChatGPT is built upon. Researchers have found that when these types of models become large enough, extraordinary capabilities emerge.
But bigger models also require more time and money to train. The training process involves showing hundreds of billions of examples to a model. Gathering so much data is an involved process in itself. Then come the monetary and environmental costs of running many powerful computers for days or weeks to train a model that may have billions of parameters.
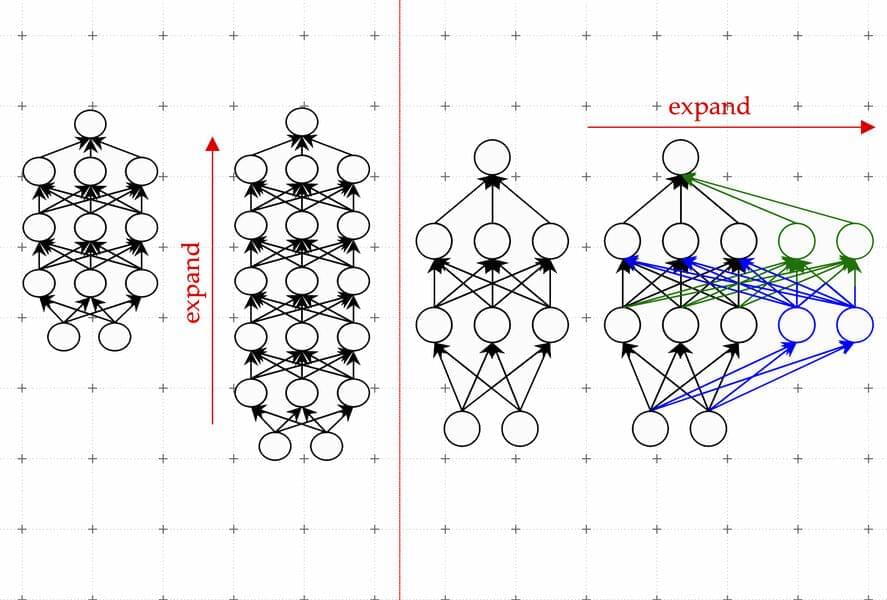
“It’s been estimated that training models at the scale of what ChatGPT is hypothesized to run on could take millions of dollars, just for a single training run. Can we improve the efficiency of these training methods, so we can still get good models in less time and for less money? We propose to do this by leveraging smaller language models that have previously been trained,” says Yoon Kim, an assistant professor in MIT’s Department of Electrical Engineering and Computer Science and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL).