Both animals and people use high-dimensional inputs (like eyesight) to accomplish various shifting survival-related objectives. A crucial aspect of this is learning via mistakes. A brute-force approach to trial and error by performing every action for every potential goal is intractable even in the smallest contexts. Memory-based methods for compositional thinking are motivated by the difficulty of this search. These processes include, for instance, the ability to: recall pertinent portions of prior experience; (ii) reassemble them into new counterfactual plans, and (iii) carry out such plans as part of a focused search strategy. Compared to equally sampling every action, such techniques for recycling prior successful behavior can considerably speed up trial-and-error. This is because the intrinsic compositional structure of real-world objectives and the similarity of the physical laws that control real-world settings allow the same behavior (i.e., sequence of actions) to remain valid for many purposes and situations. What guiding principles enable memory processes to retain and reassemble experience fragments? This debate is strongly connected to the idea of dynamic programming (DP), which using the principle of optimality significantly lowers the computing cost of trial-and-error. This idea may be expressed informally as considering new, complicated issues as a recomposition of previously solved, smaller subproblems.
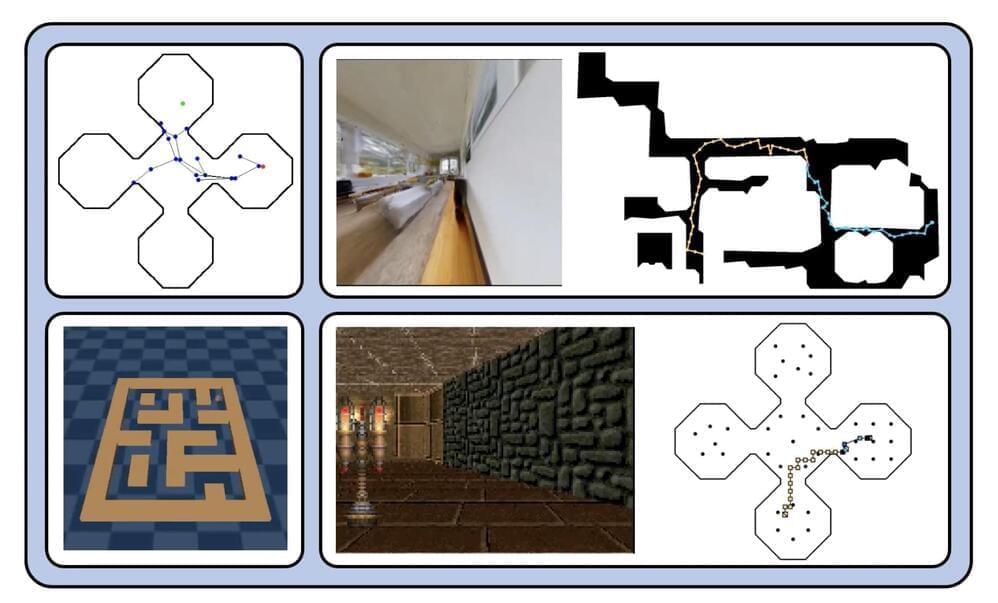
This viewpoint has recently been used to create hierarchical reinforcement learning (RL) algorithms for goal-achieving tasks. These techniques develop edges between states in a planning graph using a distance regression model, compute the shortest pathways across it using DP-based graph search, and then use a learning-based local policy to follow the shortest paths. Their essay advances this field of study. The following is a summary of their contributions: They provide a strategy for long-term planning that acts directly on high-dimensional sensory data that an agent may see on its own (e.g., images from an onboard camera). Their solution blends traditional sampling-based planning algorithms with learning-based perceptual representations to recover and reassemble previously recorded state transitions in a replay buffer.
The two-step method makes this possible. To determine how many timesteps it takes for an optimum policy to move from one state to the next, they first learn a latent space where the distance between two states is the measure. They know contrastive representations using goal-conditioned Q-values acquired through offline hindsight relabeling. To establish neighborhood criteria across states, the second threshold this developed latent distance metric. They go on to design sampling-based planning algorithms that scan the replay buffer for trajectory segments—previously recorded successions of transitions—whose ends are adjacent states.