Abstract. Adaptive evolution often leads to niche specialization, but successful colonization of a new niche can depend as much on ecological context as on


The world has far more bees than anyone realized. Scientists have, for the first time, estimated just how many species of bees are out there on a global scale, offering a clearer look at how these vital pollinators are distributed around the planet. The landmark study, led by University of Wollongong (UOW) evolutionary biologist Dr. James Dorey, provides the most comprehensive count to date—broken down by continent and country—calculating there are, at a minimum, between 3,700 and 5,200 more bee species buzzing around the world than currently recognized.
The research, outlined in a new paper published Tuesday, February 24, in Nature Communications, lifts global estimates to between 24,705 and 26,164 bee species and reveals a richer and more complex picture of the world’s bees than ever before. The findings highlight how many bee species remain unclassified or overlooked, showing that even our much-loved pollinators are not fully understood, and that closing these knowledge gaps is crucial for conservation and food security.
“Knowing how many species exist in a place, or within a group like bees, really matters. It shapes how we approach conservation, land management, and even big-picture science questions about evolution and ecosystems,” Dr. Dorey said. “Bees are a perfect example. They’re keystone species; their diversity underpins healthy environments and resilient agriculture. If we don’t understand how many bee species there are, we’re missing a key part of the puzzle for protecting both nature and farming.”
Dr. Olivier Mousis: “Our findings suggest that Jupiter’s moons did not form as chemically pristine worlds. Instead, they may have accreted, or accumulated, a significant inventory of COMs at birth, providing a chemical foundation that could later interact with the liquid water in their interiors.” [ https://www.labroots.com/trending/space/30236/jupiter-s-moon…ts-birth-2](https://www.labroots.com/trending/space/30236/jupiter-s-moon…ts-birth-2)
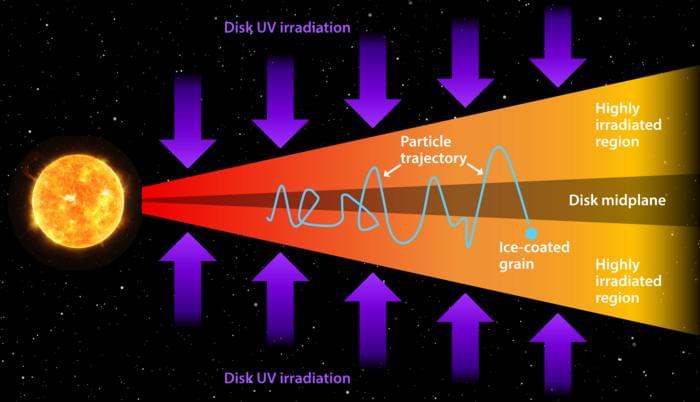
When did Jupiter’s Galilean moons first contain the ingredients for life? This is what complementary studies published in The Planetary Science Journal and Monthly Notices of the Royal Astronomical Society hopes to address as an international team of scientists investigated potential timescales for when three of Jupiter’s Galilean moons, Io, Europa, Ganymede, and Callisto, could have first formed the ingredients for life. This study has the potential to help scientists better understand the formation and evolution of the Galilean moons and what this could mean in the search for life beyond Earth.
For the studies, the researchers explored the formation of complex organic molecules (COMs) within Jupiter’s original disk of gas, dust, and ice, also called the circumplanetary disk, along with modeling how COMs could be delivered to the Jupiter system from the protoplanetary disk that formed the Sun and planets. They examined how interaction with ultraviolet radiation from the Sun could influence COM formation. The overarching goal of both studies was to ascertain both how and when Jupiter’s Galilean moons received the ingredients for life, specifically focusing on icy grains that currently comprise Europa, Ganymede, and Callisto.
In the end, the researchers found that icy grains could have obtained COMs and delivered them to Jupiter’s moons both within Jupiter’s circumplanetary disk and from the solar system’s protoplanetary disk. Additionally, the models showed that approximately half of the simulated icy grains could have formed within the solar system’s protoplanetary disk and were delivered to Jupiter’s moons. Finally, the researchers estimated these processes occurred billions of years ago during the early formation of the solar system.
Forget tentacles—what matters is the mind. We explore how alien behavior might emerge from evolution, culture, and technology, and why our biggest first contact risk may be misunderstanding.
Watch my exclusive video Mass Drivers on the Moon: https://nebula.tv/videos/isaacarthur–…
Get Nebula using my link for 40% off an annual subscription: https://go.nebula.tv/isaacarthur.
Get a Lifetime Membership to Nebula for only $300: https://go.nebula.tv/lifetime?ref=isa…
Use the link https://gift.nebula.tv/isaacarthur to give a year of Nebula to a friend for just $36.
Visit our Website: http://www.isaacarthur.net.
Join Nebula: https://go.nebula.tv/isaacarthur.
Support us on Patreon: / isaacarthur.
Support us on Subscribestar: https://www.subscribestar.com/isaac-a…
Facebook Group: / 1583992725237264
Reddit: / isaacarthur.
Twitter: / isaac_a_arthur on Twitter and RT our future content.
SFIA Discord Server: / discord.
Credits:
How Would Aliens Behave?
July 13, 2025; Episode 732
Written, Produced & Narrated by: Isaac Arthur.
Select imagery/video supplied by Getty Images.
Music Courtesy of Epidemic Sound http://epidemicsound.com/creator.
Stellardrone, \
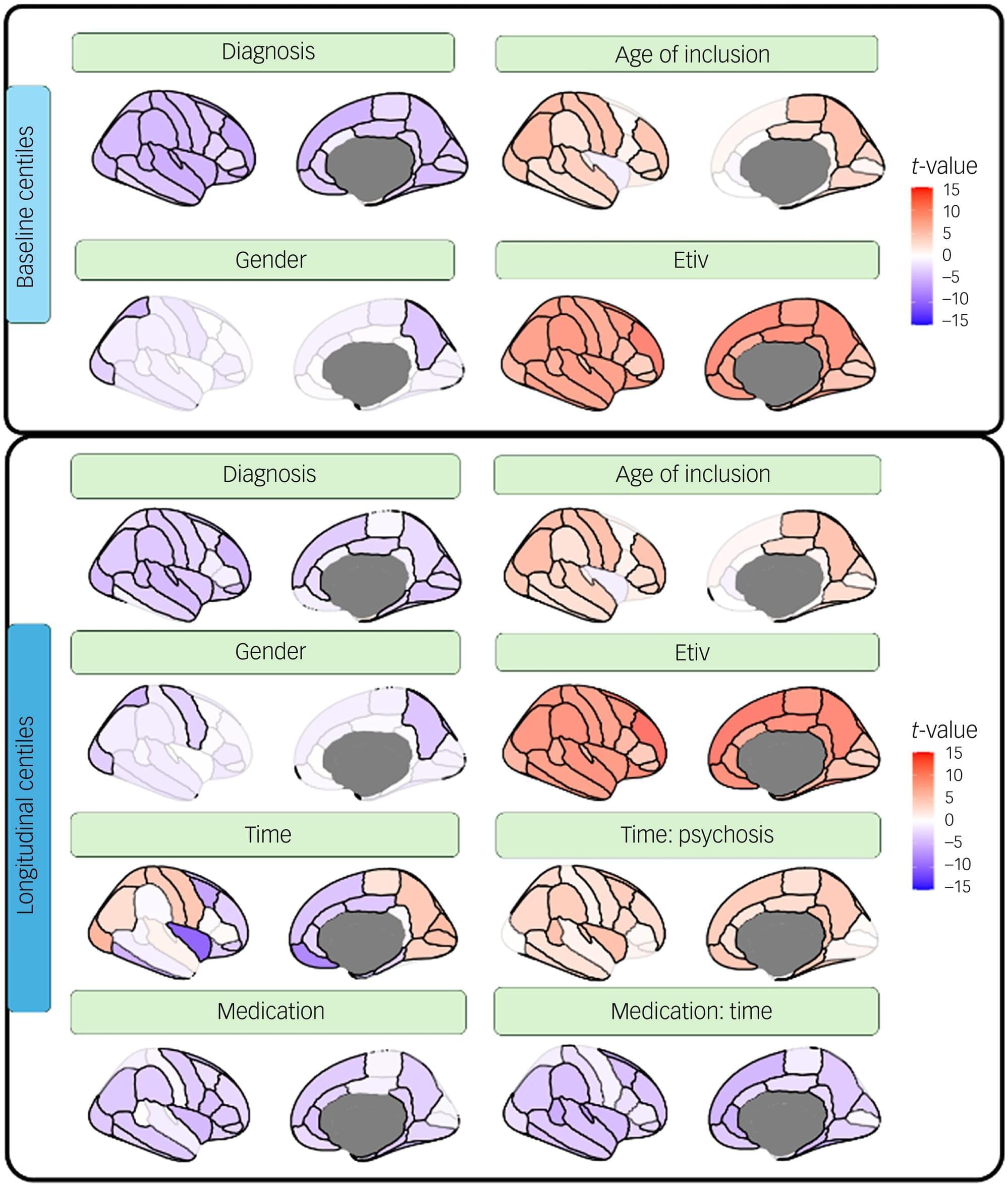
Researchers at the University of Seville have analyzed alterations in the cerebral cortex in people suffering from psychosis. Their findings show that psychosis does not follow a single trajectory, but rather its evolution depends on a complex interaction between brain development, symptoms, cognition and treatment. The authors therefore emphasize the need to adopt more personalized approaches that take individual differences into account in order to better understand the disease and optimize long-term therapeutic strategies.
Psychosis is a set of symptoms—such as hallucinations and delusions—that are common in schizophrenia and involve a loss of contact with reality. From their first manifestation, known as the first psychotic episode, these symptoms can appear and evolve in very different ways between individuals, thus making schizophrenia a particularly complex disorder.
The results of the study show that, at the time of the first episode, people with psychosis present a reduction in cortical volume, which is particularly marked in regions with a high density of serotonin and dopamine receptors, key neurotransmitters in both the pathophysiology of psychosis and the mechanism of action of antipsychotics. The data also suggest that both neurons and other brain cells involved in inflammatory and immunological processes may play an important role in the disease.

Astronomers have found an Earth-sized exoplanet, HD 137,010 b, orbiting a nearby Sun-like star but likely far too cold to be habitable.
How any Earth-sized exoplanets exist, and how do we find them? This is what a recent study published in The Astrophysical Journal Letters hopes to address as a team of scientists announced the discovery of an Earth-sized exoplanet orbiting a K-dwarf star, the latter of which is smaller and cooler than our Sun. This discovery has the potential to help scientists not only better understand the formation and evolution of Earth-like worlds, but also the methods used to find them.
For the discovery, the researchers analyzed data obtained from the NASA Kepler K2 mission about HD 137,010 b, which is located approximately 146 light-years from Earth. While the data was collected in 2017 using the transit method, which is when astronomers observe a dip in starlight as the planet crosses in front of its star, astronomers only recently were able to analyze the data to confirm this dip in starlight was an exoplanet. Despite the transit only lasting 10 hours, the astronomers estimate this means HD 137,010 b has an approximate orbital period of 355 days and an approximate radius of 1.06 Earths.

Dr. Ryan Cloutier: “We’ve seen this pattern: rocky inside, gaseous outside, across hundreds of planetary systems. But now, the discovery of a rocky planet in the outer part of a system forces us to rethink the timing and conditions under which rocky planets can form.”
What can rocky planets orbiting in the outer parts of a solar system teach scientists about planetary formation and evolution? This is what a recent study published in Science hopes to address as a team of scientists have discovered a rocky planet orbiting in the outer reaches of an exoplanetary system. This study has the potential to challenge longstanding hypotheses regarding the solar system architecture, specifically regarding rocky planets orbiting closer to their star and larger gas giants orbiting farther away.
For the study, the researchers analyzed four exoplanets in the LHS 1903 system orbiting a red dwarf star, the latter of which is smaller and cooler than our Sun. Due to the planets orbiting closer to their star than our planets orbiting our Sun, the researchers estimated the orbital periods for the four exoplanets were between 2.2 and 29.3 days. However, the researchers were surprised to discover that while the innermost planet was rocky and the second the third planets were gaseous, the outermost planet was also rocky. As a result, this finding contradicts longstanding notions about solar system architecture, specifically regarding our own solar system that rocky planets orbit closer to the star while outer planets are gaseous.
In contrast with modern birds, the Cretaceous theropod dinosaur Microraptor possessed multiple wings, with long feathers on its arms, legs, and tail. The flight capabilities of Microraptor are not well-understood. Csaba Hefler et al. analyzed the aerodynamics and forewing–hindwing interactions of Microraptor based on anatomical data from more than 100 fossilized specimens. The authors modeled fixed-wing gliding flight with the wings of Microraptor at low, moderate, and high angles of attack, which represent angles between the body axis and the direction of incoming air flow. The modeling suggested that synergistic interactions between vortices created by the leading edges of the forewings and hindwings could have provided a substantial and sustained boost to lift while gliding under a variety of conditions. The simulated forewing–hindwing interactions resemble aerodynamic effects seen in dragonflies. Vortices formed by the distinctively flared tip of the Microraptor hindwing contributed additional lift, a specialized feature not seen in other early multiwinged birds, such as Archaeopteryx and Anchiornis. The analysis suggests that Microraptor likely used aerodynamic features comparable to those seen in modern flying animals while gliding. According to the authors, the findings push back the evolution of sophisticated flight dynamics to the Early Cretaceous Period. — M.H.

“Since the Apollo era, we’ve known about the prevalence of lobate scarps throughout the lunar highlands, but this is the first time scientists have documented the widespread prevalence of similar features throughout the lunar mare,” said Dr. Cole Nypaver.
Does our Moon exhibit recent tectonic activity? This is what a recent study published in The Planetary Science Journal hopes to address as a team of scientists investigated the potential for our Moon to have exhibited recent tectonic activity despite its interior not being geologically active. This study has the potential to help scientists better understand the processes responsible for tectonic activity on planetary bodies and what this could mean for the formation and evolution of planets and moons throughout the cosmos.
For the study, the researchers created the first global map of small mare ridges (SMRs) on the Moon, which are small, narrow tectonic ridges located within the lava plains on the Moon and are similar to lobate scarps, another frequently observed geologic formation on the Moon. They have been hypothesized to result from the Moon shrinking as it’s cooled over billions of years, with the top crust bucking under the pressure of compression.
Using a combination of lunar global mosaics and images from the Lunar Reconnaissance Orbiter Camera (LROC) Narrow Angle Cameras (NACs), the researchers successfully identified and mapped more than 1,100 new SMRs across the nearside of the Moon. Through this, the researchers demonstrated these SMRs are geologically young compared to the surrounding regions and are widely distributed among the lunar volcanic plains.