With avowed ‘massive gamer’ Mohammed bin Salman at the helm, the kingdom’s insatiable appetite and bottomless riches are already remaking the global video game industry.
You could call it the summer that Saudi Arabia swallowed sports.

This video is about My Movie.
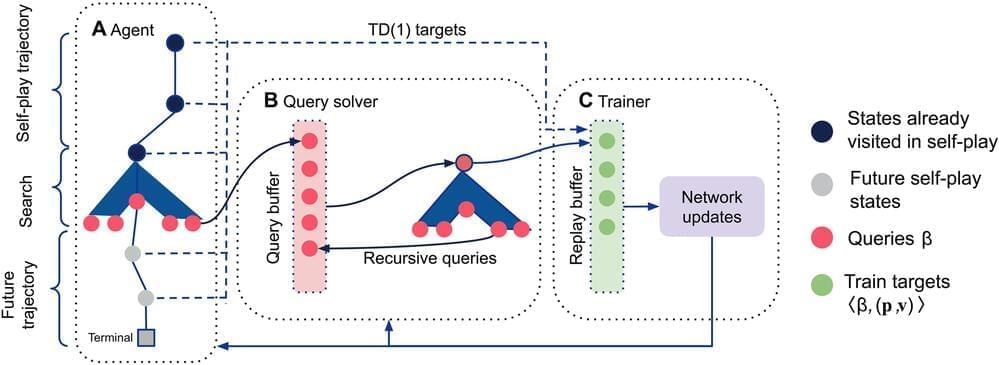
A team of AI researchers from EquiLibre Technologies, Sony AI, Amii and Midjourney, working with Google’s DeepMind project, has developed an AI system called Student of Games (SoG) that is capable of both beating humans at a variety of games and learning to play new ones. In their paper published in the journal Science Advances, the group describes the new system and its capabilities.
Over the past half-century, computer scientists and engineers have developed the idea of machine learning and artificial intelligence, in which human-generated data is used to train computer systems. The technology has applications in a variety of scenarios, one of which is playing board and/or parlor games.
Teaching a computer to play a board game and then improving its capabilities to the degree that it can beat humans has become a milestone of sorts, demonstrating how far artificial intelligence has developed. In this new study, the research team has taken another step toward artificial general intelligence—in which a computer can carry out tasks deemed superhuman.

Backlash on using AI to redub video game lines.
Naruto’s latest fighting game faces criticism for some questionable voiceover lines, leading to accusations of AI manipulation.
Naruto X Boruto: Ultimate Ninja Storm Connections is the newest brawler based on the hugely popular anime series (which itself adapts the hugely popular manga). Rather than purely adapting one part of the anime, however, Naruto X Boruto skims through almost the entire saga and adapts events already covered in previous games. But when comparing the new game’s dub to those previous entries, fans have been left confused.


AI has mastered some of the most complex games known to man, but models are generally tailored to solve specific kinds of challenges. A new DeepMind algorithm that can tackle a much wider variety of games could be a step towards more general AI, its creators say.
Using games as a benchmark for AI has a long pedigree. When IBM’s Deep Blue algorithm beat chess world champion Garry Kasparov in 1997, it was hailed as a milestone for the field. Similarly, when DeepMind’s AlphaGo defeated one of the world’s top Go players, Lee Sedol, in 2016, it led to a flurry of excitement about AI’s potential.
DeepMind built on this success with AlphaZero, a model that mastered a wide variety of games, including chess and shogi. But as impressive as this was, AlphaZero only worked with perfect information games where every detail of the game, other than the opponent’s intentions, is visible to both players. This includes games like Go and chess where both players can always see all the pieces on the board.
Are gamers paving the way to the future?
The future is now — or so it seems. @perrikaryal is a gamer, Twitch streamer, psychology graduate and a genius with the ability to control games…with her mind! She has mastered the art of doing this with games like Elden Ring, Halo and TrackMania all without using a controller. To do this she uses an EEG (electroencephalogram) that picks up her brain activity, which then translates into pushing buttons on a virtual controller.
Is mind control the future of gaming?
00:00 Intro.
00:20 What is mind control gaming?
01:03 What does brain activity look like?
02:08 How did you make it work?
04:02 James steps in the gaming ring.
05:30 Mind control gaming IS for everyone.
07:42 Bloopers!
#Games #Twitch #Brain.

Like “Avengers” director Joe Russo, I’m becoming increasingly convinced that fully AI-generated movies and TV shows will be possible within our lifetimes.
A host of AI unveilings over the past few months, in particular OpenAI’s ultra-realistic-sounding text-to-speech engine, have given glimpses into this brave new frontier. But Meta’s announcement today put our AI-generated content future into especially sharp relief — for me at least.
Meta his morning debuted Emu Video, an evolution of the tech giant’s image generation tool, Emu. Given a caption (e.g. “A dog running across a grassy knoll”), image or a photo paired with a description, Emu Video can generate a four-second-long animated clip.

