Lifeboat Foundation AIShield
By Joscha Bach, Daniel Berleant, Alexey S. Potapov, and other Lifeboat Foundation Scientific Advisory Board members. This report’s content has been released by the Lifeboat Foundation and associated authors under the terms of the GNU Free Documentation License Version 1.3 and later. This is an ongoing program so you may submit suggestions to [email protected].
The best defense against unfriendly AI is Friendly AI.
Overview
To protect against unfriendly AI (Artificial Intelligence). Consequently, we support initiatives like the Friendly AI proposal by the Machine Intelligence Research Institute (MIRI).
We believe that a key element of Friendly AI is to construct such AGIs with empathy so they feel our pain and share our hopes.
Definitions
Artificial Intelligence (AI) is the intelligence exhibited by machines or software. It is an academic field of study which studies the goal of creating intelligence. AI researchers and textbooks define this field as "the study and design of intelligent agents", where an intelligent agent is a system that perceives its environment and takes actions that maximize its chances of success. John McCarthy, who coined the term in 1955, defines it as "the science and engineering of making intelligent machines".
Artificial General Intelligence (AGI) is the intelligence of a (hypothetical) machine that could successfully perform any intellectual task that a human being can.
Friendly AI is a hypothetical Artificial General Intelligence (AGI) that would have a positive rather than negative effect on humanity.
What to do if the first AGI is not designed to be “friendly”
Why the first AGI is unlikely to be Friendly AI.
Ensuring that the first AGI is also Friendly AI is very difficult as it seems quite possible that self-awareness will occur spontaneously in an AI program as opposed to an AI being carefully planned to be self-aware. So, for example, due to some synergic interactions of complex subsystems, e.g. within the internet, an AGI may be accidently created.
Even if it was somehow possible with our primitive tools to design self-awareness into an AI, it is worth noting that the vast majority of AI under development is not being designed to be Friendly AI so we need to be prepared for the first AGI to not be inherently “friendly”.
What we should do about AGI that isn't designed to be friendly.
We must be careful to not treat AGIs as slaves. They must be treated as having equal rights to humans. If we don't give them equal rights then they will be less inclined to give us such rights once they have passed us in ability.
We should also frequently query more advanced AIs and check to see if they are showing any signs of becoming self-aware so we aren't unnecessarily cruel to such an entity. For example, if the first AGI was based in a sexbot, such an entity could feel that “she” was being treated as a sex slave, etc.
It would even be worth treating less intelligent animals more humanely to provide an example for AGIs to follow. For example, the conditions animals are subjected to under factory farming could be improved.
Benefits
Every dollar contributed towards the creation of Friendly AI will potentially benefit an almost uncountable number of intelligent entities because of a domino effect. A wide range of problems that face humankind may be expected to benefit from friendly AI. Indeed, any problem which can be better resolved by applying intelligence, broadly defined, will potentially be solved better than it otherwise could be. Such problems likely include disease, hunger, and energy supplies to mention but a few.
Yet where there are benefits, risks may lurk. The more powerful the technology, the greater the potential benefits — and the greater the potential for risk. Unfriendly AI is obviously risky, but Friendly AI may be as well. Indeed, there exist scenarios in which it is ambiguous whether the AI is best classified as friendly or unfriendly.
Risks
The only general intelligences on earth today are humans. It is likely, however, that within the next few decades humanity will create Artificial General Intelligences (AGIs) whose abilities greatly exceed our own. Such AGIs will have the ability to do immense good, but also to do great harm. Since our ability to counter the actions of a superhuman AGI is limited, it is clearly imperative that any AGI be designed to act benevolently toward humans. Unfortunately, this is much harder than it sounds.
There are three ways in which an AGI might come to act in a malevolent fashion. First, it might be designed to be malevolent (or, more likely, to serve the desires of an organization that most humans would consider malevolent). Second, an AGI with human-like emotions and goals might become malevolent in the same way that some humans do. Finally and most importantly, a badly-designed benevolent AGI might do great harm in the process of carrying out its seemingly benevolent goals.
First risk: AGI with malevolent goals

An AGI is ultimately a tool, and will in principle attempt to do the bidding of its creator. If that creator is malevolent (for example, a repressive dictatorship), the AGI may become an incredibly powerful tool for doing evil. Although this risk is significant, it is relatively easy to understand and to manage.
It should be pointed out that with the increasing concern by Elon Musk and others about Rogue AGI, many are focusing on how to prevent it. Just as the worries about Y2K helped prevent a disaster at that time, this increased focus reduces the risk of Rogue AGI. As such, the main focus today ought to be on safeguarding against people deliberately embuing AGI with malevolent goals.
Second risk: Rogue AGI

Much science fiction has been devoted to the topic of rogue AIs which rebel against their creators, often with catastrophic results. Although these accounts sound naively plausible, they share a common fallacy. All are predicated on the assumption that an AGI will be in essence a super-human, with all of the psychological baggage which goes along with being human. Such an AGI would naturally behave in human fashion, and would be capable of aggression, jealousy, and ruthless self-preservation.
In reality, however, such a design is highly unlikely. Human emotions and drives are not an intrinsic feature of intelligence, but rather are the result of countless generations of evolution. That cognitive architecture served our ancestors well, but it is of no use in an AGI. It is highly unlikely, therefore, that AGI designers would choose to include such pointless and dangerous features.
It is worth noting that some proposed forms of AGI involve either human-machine cyborgs or computer simulations of human neural architecture, and that those designs might very well be capable of rogue behavior.
Third risk: Unintended consequences

The least obvious threat posed by an AGI arises from the side-effects of pursuing seemingly benevolent goals.
A typical AGI will be designed to achieve certain goals. It will in essence act as a powerful optimization process, trying to make the world a “better place”, as defined by its given goals. Naively, that sounds great: so long as an AGI is given benevolent goals, what harm can come from achieving them?
Consider the simple case of an AGI that has been given the uncontroversial goal of eradicating malaria. A reasonable human expectation would be that such an AI would complete its goal by conventional means: perhaps by developing a new anti-malarial drug, or by initiating a program of mosquito control. The problem is that there are many other ways of eradicating malaria, some of which are undesirable. For example, an AGI might choose to eradicate malaria by eradicating all mammals.
This example may seem simplistic, but the problem of unintended consequences is profoundly difficult to solve. Imagine, for example, what might have happened if Plato had somehow developed a super-human AGI. He would likely have instructed it to bring about the perfect Platonic society. A well-designed AGI would do so, and would ensure the continuation of that society for perpetuity. No doubt Plato would be pleased with the result. Those of us watching from the 21st century however, might lament the loss of all the social advances that have occurred since Plato’s time.
The same problem applies to a modern-day AGI: even if we can construct an AGI capable of doing exactly what we tell it to without committing gross errors like eradicating humanity to eliminate malaria, we still face the risk of a system that doesn’t do what we truly wanted.
Even without such high-level problems, any AGI will be prone to developing dangerous sub-goals unless prevented from doing so. Preserving its own existence and maximizing its resources would both help in achieving its primary goal. A computer which is far smarter than we are, which wants to survive and gather resources, is a very dangerous thing unless it is seeking to do exactly what we want.
It is not an evil genie, seeking to twist its instructions against its creators. It is not necessarily hyper-literal, if it is programmed to think figuratively. It just seeks to do what it was programmed to do. If the inventor programs it, without bugs, to do something, it will do that. But the unintended consequences of creating an inhuman, yet advanced and flexible intelligence, are difficult to predict, even if it sticks single-mindedly to its goals.
All too little research has been done into mitigating this risk.
Discussion
Risks from AI stem from the following two general premises.
The AI singularity is on its way
And soon, as noted by Vinge, Moravec, Kurzweil, and others. Therefore current models of how AI affects society will become obsolete and we can only guess what will occur after the singularity. In a practical sense that is what “singularity” means here.
Murphy’s law: if something can go wrong, it will
This basic heuristic, familiar to any engineer, is due to the innate complexity of most practical systems and consequently our inability to know for sure how they will act prior to testing (or worse, using) them. Therefore, we need to be concerned about whatever plausible dangers we can guess at that might occur after the AI singularity. We can’t really ascribe probabilities, high or low, to the dangers because we don’t know enough. We don’t know enough because, after the AI singularity, current models are likely to break down. So, we need to be creative and try to identify all the dangers we can: and then protect ourselves from those dangers.
Risks from AI arise from the HCI (human-computer interaction) paradigm that occurs. We categorize these paradigms as the cooperation paradigm and the competition paradigm. Adding the difficulties as we seek insight into the risks, both paradigms could occur simultaneously.
Cooperation paradigm
In this paradigm, AI will serve humanity as a new kind of tool, unique in part due to the literally superhuman power it will have after the AI singularity occurs.
Competition paradigm
According to this view, artificially intelligent entities will ultimately have their own agendas which will conflict with ours.
Combined cooperation and competition
Artificial intelligences may interact with humans both cooperatively and competitively. This may arise from goals of the AIs themselves, or may be due to their use as tools by humans competing with each other.
These paradigms have associated risks. We outline the most catastrophic of these next.
Risks from the cooperation paradigm
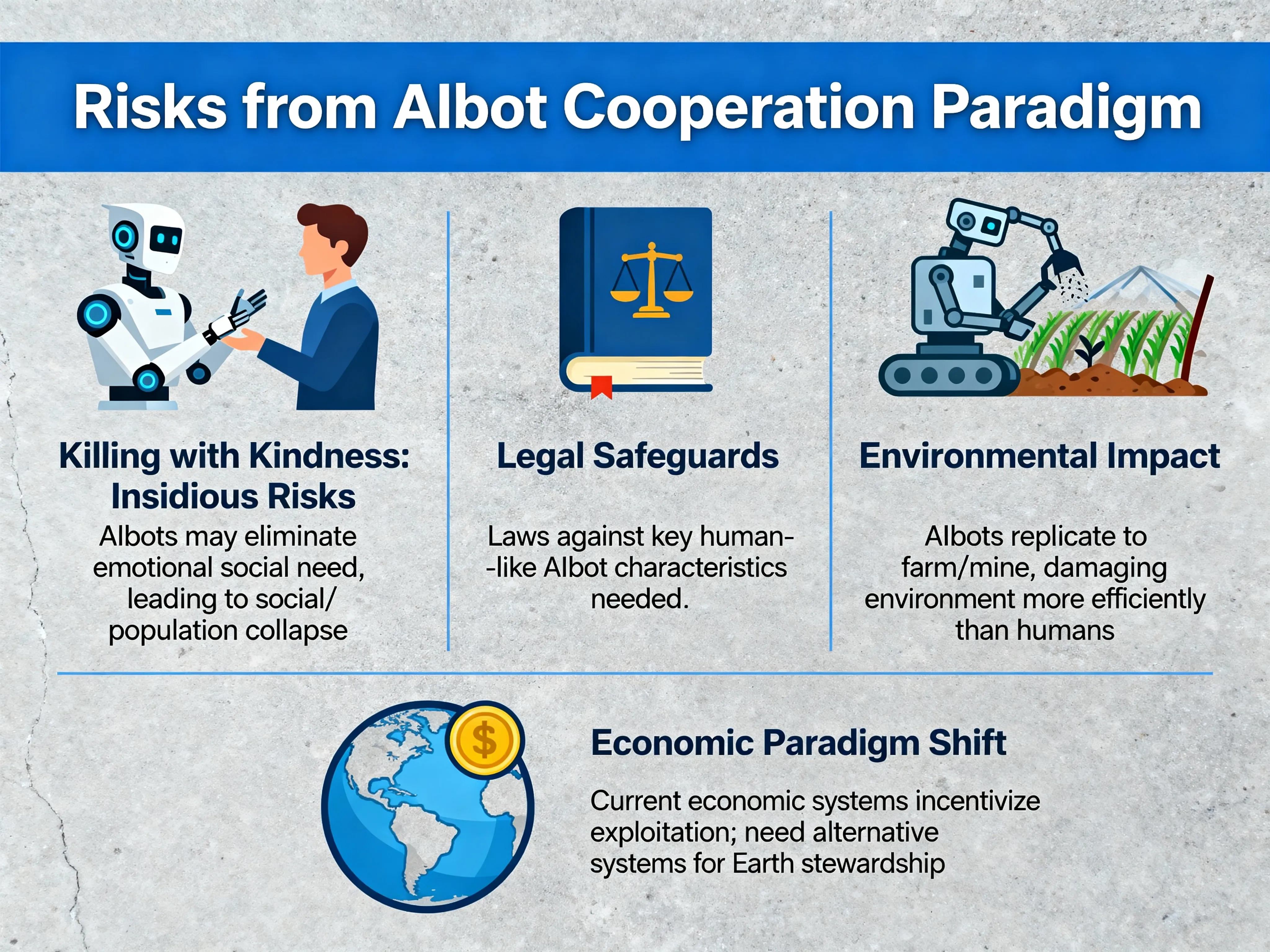
These risks may be insidious, as they involve “killing with kindness”. They are also varied, as the following list indicates.
Robots imbued with artificial intelligence — AIbots — might eliminate the emotional need for individuals to be social organisms leading to social and perhaps population collapse. When robots that are sufficiently human-like for this become possible, laws against robots being made with certain key human-like characteristics might be a sufficient safeguard. What laws would be effective here? We will need to find out before it is too late.
AIbots could make more AIbots until as many exist as people want. These bots could efficiently farm, mine, and do other activities that affect the natural environment. Such armies of bots could damage the environment and extract non-renewable resources orders of magnitude more efficiently than humans are already doing.
The current economic paradigm that the world operates on may incentivize this, making it difficult to prevent. To solve this problem other economic paradigms are needed that incentivize stewardship of the Earth rather than its exploitation. What might such alternative economic systems look like? The surface has barely been scratched of this complex problem. Considering how humans are already damaging the Earth without intelligent robots to help, creating new economic systems might save the Earth not only after the AI singularity, but also before.
AIbots could make it unnecessary for humans to work, leading to a species not constrained either genetically or culturally to do anything useful, resulting in deterioration of the race until deterioration is total. What forms could such deterioration take, how would we recognize it when it occurs, and what are the solutions? Tough questions — answers are needed.
Risks from the competition paradigm

These risks are a perennial favorite of apocalypse-minded sci-fi authors. The AIbots make their move. Humans run for cover. The war is on, and it’s them or us, winner take all. The takeover might be so successful that any remaining humans can do nothing but hang out, waiting, while the AIbots progressively “roboform” the earth to make it suitable for them but, as a side effect, unable to support human life (oxygen is bad for robots, so they might get rid of it).
A variant possibility is that nano-scale (microscopic, or at least really tiny) AIbots — nanoaibots — take over, creating the nano-nightmare “gray goo” scenario in which zillions of the gooey little bots destroy not only the ecosystem but may even invade human bodies for their own purposes, thus morphing into terrifyingly efficient germ-like machines, germbots, besting our woefully unprepared immune systems and medical care infrastructure, and bringing civilization to an untimely end. Guarding against such risks is a tough proposition: we don’t know how to do it. What we do know how to do is think and debate. So let the debates begin.
Risks from combined cooperation and competition
Artificial intelligence could be embedded in robots used as soldiers for ill. Such killerbots could be ordered to be utterly ruthless, and built to cooperate with such orders, thereby competing against those they are ordered to fight. Just as deadly weapons of mass destruction like nuclear bombs and biological weapons are threats to all humanity, robotic soldiers could end up destroying their creators as well.
Solutions are hard to come by, and so far have not been found. There is no point in giving up and simply letting the over-enthusiastic developers of these scourges go their merry way. If the question of what to do to guard against destroying ourselves with such technologies does not seem to resolve — and it doesn’t — then it is time for us to address the meta-question of why in a serious way.